Overview of the AMD enterprise AI reference stack#
The AMD enterprise AI reference stack is an opinionated software stack for developing, deploying, and running AI workloads on a Kubernetes platform optimized for AMD compute. The platform can be utilized by system administrators, resource managers, AI researchers, and AI solution developers.
Key features#
Optimized GPU utilization and lower operational costs
High GPU efficiency through intelligent workload placement and dynamic resource sharing eliminates waste, reduces costs, and guarantees fair access to compute power—empowering teams to innovate without delay.
Unified AI infrastructure
The reference stack consolidates fragmented environments into a cohesive AI ecosystem. With standardized governance, tools, and processes, the reference stack simplifies operations and enables seamless collaboration across teams and business units.
Accelerated time-to-value
Built-in inference and a streamlined development process minimize the time to get your AI models to production, enabling you to go from bare metal or cloud to running production workloads in a matter of minutes.
AI-native workload orchestration
Unlike traditional schedulers, the reference stack is optimized for AI. It intelligently prioritizes jobs, dynamically allocates resources, and ensures consistent performance, maximizing the utilization of compute infrastructure. A catalog of portable inference microservices for serving AI models on AMD Instinct™ GPUs is included.
Enterprises reduce complexity, accelerate AI deployment, and maximize ROI—turning AI from a cost center into a strategic advantage.
Information security
The reference stack offers built-in Role-Based Access Controls (RBAC) and the possibility to federate and integrate with existing SSO and IAM solutions.
Key components of the reference stack#
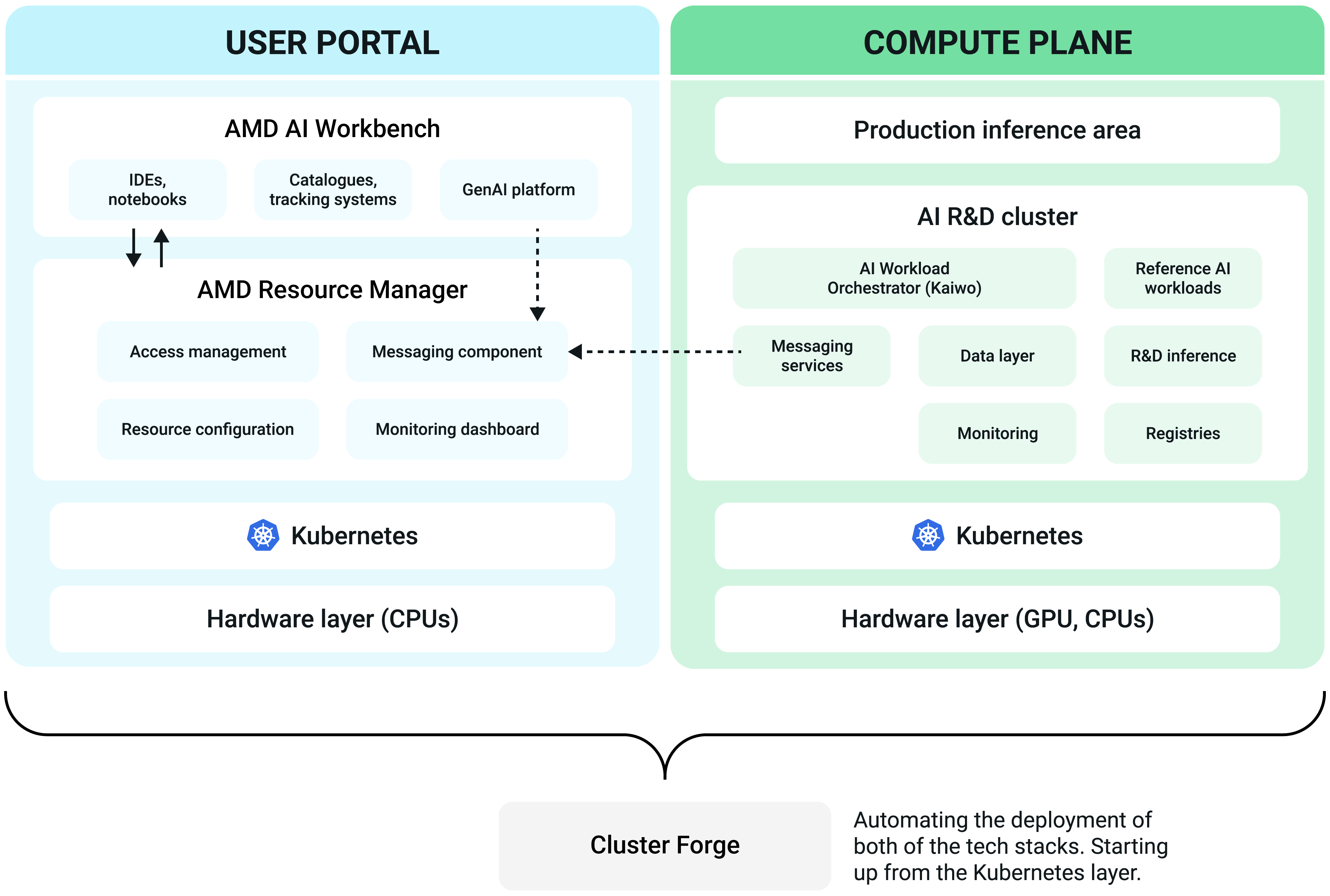
AMD AI Workbench
AMD AI Workbench enables researchers to manage AI workloads end-to-end. AMD AI Workbench focuses on user experience, offering low-code approaches for developing AI applications by simplifying the execution of fine-tuning, inference, and other jobs.
Focusing on user experience, AMD AI Workbench has a comprehensive model catalog, enabling AI researchers to better understand which models, data, and workloads they can use and download for their work. Additionally, AMD AI Workbench offers (and aims to expand) integrations with well-established MLOps tools such as MLflow and TensorBoard, allowing researchers to use the AI development tools that feel most natural to them.
AMD Resource Manager
With AMD Resource Manager, enterprises can manage resource utilization on the R&D compute cluster by mapping user groups to compute, data, and image resources. Resource Manager maximizes GPU usage by allowing projects and user groups to share GPUs and by configuring compute clusters with policies that enable fair and smart scheduling. Administrators can monitor GPU utilization at the project, department, cluster, and enterprise levels using dashboards.
Kaiwo (Kubernetes - AI Workload Orchestrator)
Kaiwo optimizes GPU resource utilization for AI workloads by minimizing GPU idleness. The workload scheduler increases resource efficiency through intelligent job queueing, fair sharing of resources, guaranteed quotas, and opportunistic gang scheduling. It controls the deployment of AI workloads by implementing a Kubernetes operator that watches for the deployment of AI workloads. Main functions:
Decides where and when workloads will be executed based on compute policies
Supports multiple queues, fair GPU resource sharing, topology-aware scheduling, and other features. Open sourced at silogen/kaiwo
Kubernetes platform
The core orchestration platform for managing containerized applications. Kubernetes is the industry standard for orchestrating containerized applications at scale. It provides the flexibility, scalability, and reliability needed to support enterprise AI workloads—from training machine learning models to serving predictions in production.
Cluster Forge
A tool built to help enterprises easily deploy the reference stack using open-source technologies. Cluster Forge automates the deployment of the control and compute planes onto Kubernetes clusters, integrates prepackaged AI workloads, and enables organizations running on AMD hardware to start training and deploying models within just a few hours—essentially offering a streamlined, “one-click” setup for enterprise-grade AI infrastructure.
AMD Inference Microservices (AIMs)
Serving AI models in general and LLMs in particular is not a trivial task. AIMs, short for AMD Inference Microservices, abstracts away the complexities involved in configuring and serving AI models by providing a mechanism to automatically choose optimal runtime parameters based on the user’s input, hardware, and model specifications. The catalog of pre-developed AI microservices is continuously updated. Learn more about AIMs.
Solution Blueprints
Solution Blueprints are reference applications built with AIMs that demonstrate their use within a complete microservice solution. They provide developers with example implementations and starting points for building real-world solutions using ROCm software. Solution Blueprint Helm charts are off-the-shelf ready to deploy to a Kubernetes cluster running AMD compute, and templating allows the applications to be easily customized. Since AI models typically require integration with external systems and services, Solution Blueprints include documentation and architecture diagrams that illustrate how the components interact within a functional application.