Fine-tuning#
Fine-tuning a model allows you to customize it for your specific use case with your data. We provide a certified list of base models that you can fine-tune, and allow you to customize certain hyperparameters to achieve the best results.
Fine-tuned models can be deployed and subsequently used for inference once the model weights have been computed.
Getting ready to fine-tune your model#
Prerequisites for new projects#
Important
Required for New Projects: Fine-tuning requires access to internal cluster storage. If you are working with a new project, you must assign the pre-installed minio-credentials-fetcher secret to your project before you can perform fine-tuning operations.
To assign this secret:
Navigate to Resource Manager → Secrets
Find the
minio-credentials-fetchersecret in the listClick the actions menu (⋮) and select Edit assignment
Select your project from the list and click Save changes
For detailed instructions on managing secret assignments, see the Manage secrets guide.
Uploading training data#
One of the first steps toward fine-tuning your model is to upload training data to our platform. The training data should represent a wide range of conversations that you would like your model to respond to as part of inference.
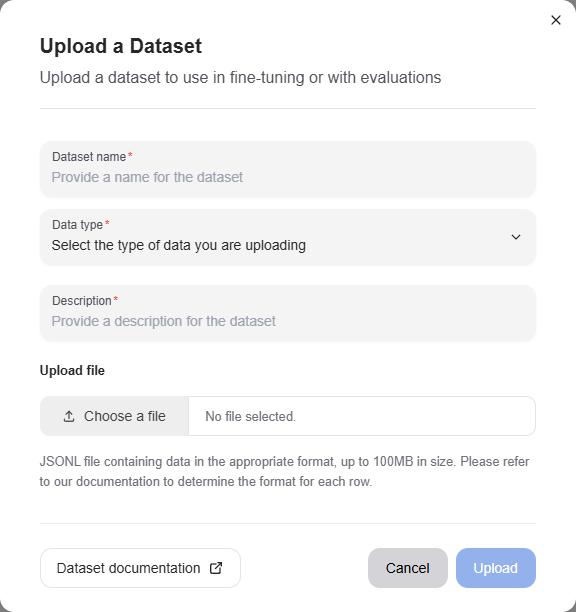
Once you have procured training data for your model, navigate to the “Datasets” page of the AMD AI Workbench to upload the dataset. We currently support uploading datasets in a JSONL format, where each row represents a separate chat conversation. The format of each row should correspond to what is defined in the specification for each datapoint.
Click the “Upload” button and drop your JSONL file in, providing a name and description.
Base models for fine-tuning#
We continuously work to certify base models for fine-tuning. It is recommended that you first identify a base model appropriate for your use case and use that for fine-tuning. If you are missing a specific base model, reach out to our customer success team so they can either provision access or fast-track certification.
You can browse the list of accessible base models by navigating to the Models page, going to the Custom models tab, and clicking the “Fine-tune Model” button to see available base models in the “Select base model” dropdown.
Creating a fine-tuned model#
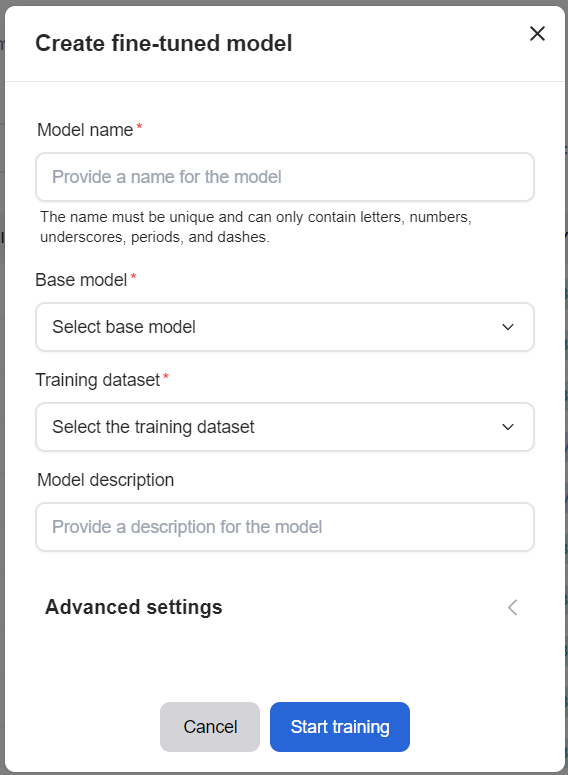
Navigate to the Models page and go to the Custom models tab. You can trigger the creation of your fine-tuned model by clicking the “Fine-Tune Model” button and selecting the appropriate entries.
You must provide your model a name, select a base model, select a dataset, and provide a Hugging Face token. You can optionally specify a description and any of the three hyperparameters: batch size, learning rate multiplier, and number of epochs. If you are unsure of the values to use, leave the fields empty to auto-select the default certified values.
Note
Hugging Face Token Required: You must provide a Hugging Face token for fine-tuning operations. You can either create a new token or select an existing one from your project secrets. The token will be stored as a Kubernetes secret and appear in the Secrets tab. For more information about managing secrets, see the Secrets documentation.
Alternatively you can use an already fine-tuned model as a base model for further fine-tuning by selecting the Fine-tune option from the action menu of an existing fine-tuned model in the Custom Models tab.
Once the fine-tuning process has been successfully triggered, you will be able to see your model in the “Not-deployed” tab of the page and the fine-tuning run itself in the “Run status” section. The fine-tuning run may take several hours to complete, so we recommend visiting the AMD AI Workbench occasionally while the run is in progress. If the run fails mid-way, please reach out to our customer success team, and we will help triage your issue.
Deploying a fine-tuned model#
Once your model has been successfully trained, the model status will reflect as “Ready”. This means that the weights have been successfully computed for your model and it can be used for inferencing.
Click the “Deploy” button corresponding to the model you would like to deploy to make it available for inferencing. Please note that a model, once deployed, can take up to 5 minutes before it can serve requests.
Once deployed, you can navigate to the Chat page to converse with the model.
After you have verified that your model performs as expected, you can click the “View Code” menu item on the row in the Models page and use the code snippet for inference via the API.
Undeploying a fine-tuned model#
Once you have deployed a version of a fine-tuned model, you might want to “Undeploy” it if it has been superseded by another model. You can do this by navigating to the Deployed models page, identifying the model in the list, and clicking the “Undeploy” button.
This will make the model no longer accessible for inferencing.